CURSO DE ENGENHARIA DE SOFTWARE APLICADA A CIÊNCIA DE DADOS (CD)
Classificação da qualidade de um vinho

Desenvolvimento
Atividade 2Comparação de Modelos de Machine Learning (ML) de Classificação (ou Regressão) utilizando boas práticas de Engenharia de Software.
Explorar as propriedades fisico-química de um vinho para saber como elas influenciam na classificação da qualidade de um vinho (obtida sensorialmente por especialistas, através de pontuação da qualidade de 0 a 10)
Professores: Marcos Kalinowski (Phd), Tatiana Escovedo(Phd) e Hugo Villamizar(Doutorando)
Walter Dominguez(MSc)
dez/2022

(requisitos da necessidade info / hipótese)
(necessidade info / hipótese)

Processo de produção
Onde esta a Ciência de Dados no contexto do século XXI

A Ciência dos Dados esta complementando o eixo da Ciência da informação estando as Ontologias como o outro eixo da Ciência da informação.
A Ciência dos Dados esta no contexto dos dados não estruturados enquanto as ontologias estão no eixo dos contextos estruturados.
A Engenharia de Software é orientada a frameworks que incluem Waterfall, Spiral, sistemas ágeis e muito mais. A ciência de dados inclui ferramentas de visualização de dados, ferramentas de análise de dados e ferramentas de banco de dados.
Tipos de Sitemas x Estrutura empresarial

Atividade prática de especificação de sistemas habilitados em ML
Assunto
Comparação de Modelos de Machine Learning de Classificação (ou Regressão) Utilizando Boas Práticas de Engenharia de Software.Cenário
Este trabalho deverá ser feito individualmente e deverá ser entregue até as 23h59 do dia determinado. Escolha uma base de dados para um problema de classificação ou regressão. Sugere-se usar uma das bases de dados disponibilizada no UCI Machine Learning Repository. Você deverá trabalhar desde o problema até os resultados.
Abordagem

Lembretes
Lembre-se das etapas para implementação de projetos de ciência de dados, apresentadas em sala de aula, e trabalhe com esta base de dados no ambiente Google Colab, utilizando Python e a biblioteca Scikit-Learn. Produza um notebook que servirá como relatório, descrevendo textualmente cada uma das etapas do seu código. Para a definição do problema, descreva uma user story e seu detalhamento (simplificado – não é necessário utilizar o template de especificação da atividade anterior, já que é um toy problem e não um projeto industrial), na primeira célula do notebook. Para a implementação, sugere-se utilizar as boas práticas de programação orientada a objetos trabalhadas em sala. Após a entrega, caso ainda não tenha respondido, responda ao survey de finalização da disciplina.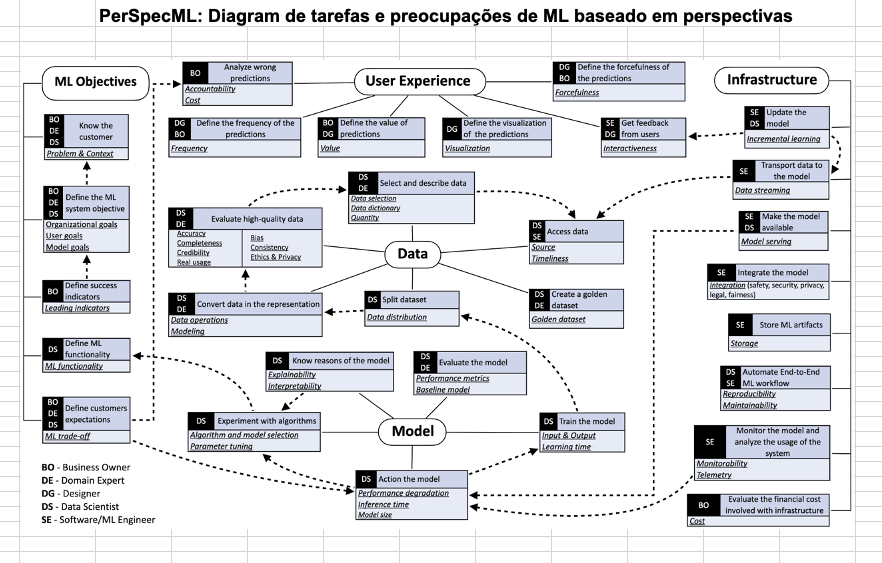
PROCESSO DE PRODUÇÃO DO PRODUTO ML

Abordagem de projeto
Método de solução de problema:
Partir do problema resolvido. Como seria a solução?
[Página WEB insigt] :https://rpubs.com/Zarzar/555952
Usar o Colab book do caso completo da Diabete
[Página WEB] :https://colab.research.google.com/drive/1rEzxfxvDqqHmXVJjQM6LXi-ZhShMhWsx?usp=sharing
Método de desenvolvimento:
Processo em cascata, usando processo de Prototipagem tendo como ferramenta notebook em python no ambiente colab.research.google.com
Método de aprendizagem e documentação do projeto
Construir uma página web dividida em seções de aprendizagem. Cada seção contém o estudo de caso divido por etapas
e sintisa o aprendizado. O critério de divisão é pelas etapas de um projeto de produto ML.:
[Página WEB] : https://olivroqueaprende.com/Curso/Atividade2/Atividade2.html ![]()
O código da execução do trabalho
Será feito em 1 (um) notebook dividido em etapas do processo de obtenção do produto ML :
1.Definição do Problema, 2. carga de dados, 3.análise de dados, 4. pré-processamento, 5. modelos de classificação, 6. apresentação do resultado.
[Notebook: ] https://colab.research.google.com/drive/1MCCMFdsGaXIQjdAYpFrqTyw0bvtXhuYb#scrollTo=n63s9EyxBQ9w ![]()
Entrega por Etapa
Interações com professores:
1.Aprovação inicial do protótipo do trabalho
2.Dúvidas na coleta e análise
3. Aprovação da modelagem e inferência
4.Envio final do trabalho
Acompanhamento do projeto
Padrão:
Critério de Aceitação
1. Ter um conjunto de dados selecionado
-
Conjunto de valores de cada caracteristica e avaliação de vinho tinto (red) winequality-red.csv

-
Conjunto de valores de cada caracteristica e avaliação de vinho branco (verde) winequality-white.csv
2. Conjunto de dados analisados
Quais propriedades fisico-química de um vinho para saber como elas influenciam na classificação da qualidade de um vinho (obtida sensorialmente por especialistas, através de pontuação da qualidade de 0 a 10)
3. Ter um site de acompanhamento
Protótipo na web para simular um framework para visualizar o projeto
Ver
[Site na Web]
![]()
4. Notebbok no Colab Google até Análise de dados
Ver
 Plataforma Google Colab
Plataforma Google Colab
Book da Atividade 2: -
5. Notebbok no Colab Google - Até pós-processamento
Ver
Plataforma Google Colab até Análise de dados
Book da Atividade 2: -
6 Notebbok no Colab Google - Apresentação de resultados
Ver
Plataforma Google Colab até Análise de dados
Book da Atividade 2: -
7 Notebbok no Colab Google - Implantação do modelo
Ver
Plataforma Google Colab Implantação do modelo
Book da Atividade 2: -
Objetivo pessoal
Saber se o esforço esta na trila certa com relação ao trabalho de modelagem de esforço individual e de uma solução sistêmica para soluções de diagnóstico e tomada decisão no desenvolvimento de sistemas de informação inteligentes tipo aprendizado de máquina (ML) .
Uso dos conceitos de engenharia de software e ciência de dados obtidos no curso: método de trabalho individual e tipo de solução de classificação
Utilizar conhecimentos em tecnologia já adquiridos de : Front-end (html,css,js)
Utilizar paradigmas de análise de sistemas de informação (essencial e orientada a objetos)
Integrar conhecimento adquirido anteriormente com novos conhecimentos em internalização
Incluir conhecimentos adquiridos para complementar base de conhecimento do meu site pessoal[Web Site pessoal]
DEFINIÇÃO DA SOLUÇÃO
Status da atividade:
-
Perguntas dos gestores.
Como as caracteristicas dos vinhos contidos no conjuntos de dados influenciam na classificaçãp do vinho ? -
Perguntas dos analistas.
Como construir um modelo de classificação que preveja sua qualidade com base nas características físicas e químicas do vinho (a qualidade do vinho foi avaliada com base em seu sabor). -
Descrição dos dados.
Os Data set foram obtidos Conjunto de dados sobre Vinho da UCI Machine Learning Repository [Web]
(em caso de dúvida consultar Home Page do Paulo Cortez
, assim como a descrição de como foram coletados os dados.).
Esse conjunto de dados organizado contém 1.599 vinhos tintos com 11 variáveis sobre as propriedades químicas do vinho. Pelo menos três especialistas em vinhos avaliaram a qualidade de cada vinho, fornecendo uma classificação entre 0 (muito ruim) e 10 (muito excelente).
-
Requisitos funcionais e não-funcionais.
Os dois conjuntos de dados:
-
Conjunto de valores de cada caracteristica e avaliação de vinho tinto (red) winequality-red.csv
-
Conjunto de valores de cada caracteristica e avaliação de vinho branco (verde) winequality-white.csv
Na referência acima, foram criados dois conjuntos de dados, utilizando amostras de vinho tinto e branco.
Em cada arquivo .csv contém:
- Entradas com elementos químicos dos vinhos (por exemplo, valor de PH por vinho).
-
Saída é baseada em dados sensoriais
(mediana de pelo menos 3 avaliações feitas por peritos em vinho - ruim, médio e excelente).
Cada perito avaliou a qualidade de cada vinho entre 0 (muito mau) e 10 (muito excelente).
-
Conjunto de valores de cada caracteristica e avaliação de vinho tinto (red) winequality-red.csv
-
Variáveis de entrada que desejam ser preditas ou descritas, assim como as que possivelmente são relacionadas.
Variáveis de entrada (com base em testes físico-químicos):- acidez fixa
- acidez volátil
- ácido cítrico
- açúcar residual
- cloretos
- dióxido de enxofre livre
- dióxido de enxofre total
- densidade
- pH
- sulfatos
- álcool
-
Variável de saída (com base em dados sensoriais):
- qualidade (pontuação entre 0 e 10)
-
Definição do problema de Ciência de dados (CD).
Como as caracteristicas dos vinhos contidos no conjuntos de dados inflenciam na classificaçãp do vinho ?
Tipo de problema: Classificação
Tipo de aprendizado: supervisionado
Utiliza dois grupos:-
X, com os atributos a serem utilizados na predição do valor
Variáveis de entrada (com base em testes físico-químicos): -
Y, com o atributo para o qual se deve fazer a predição do valor (atributo-alvo)
qualidade (pontuação entre 0 e 10)
O atributo alvo é categórico
-
X, com os atributos a serem utilizados na predição do valor
-
Fonte:
Conjunto de dados sobre Vinho da UCI Machine Learning Repository
- Informação Relevante:
Os dois conjuntos de dados estão relacionados com as variantes tinto e branco do vinho português "Vinho Verde".
Para mais pormenores, consultar: http://www.vinhoverde.pt/en/ ou a referência [Cortez et al., 2009]. Devido a questões de privacidade e logística, apenas variáveis físico-químicas (entradas) e sensoriais (saídas) estão disponíveis (por exemplo, não há dados sobre tipos de uva, marca de vinho, preço de venda do vinho, etc.).
Número de Instâncias: vinho tinto - 1599; vinho branco - 4898.
Número de Atributos: 11 + atributo de saída
Nota: vários dos atributos podem estar correlacionados, por isso faz sentido aplicar algum tipo de selecção de características.
Informação sobre os atributos:
Para mais informações, ler [Cortez et al., 2009].
- Documentos relevantes:
P. Cortez, A. Cerdeira, F. Almeida, T. Matos e J. Reis. Modelagem de preferências de vinho por mineração de dados de propriedades físico-químicas.
Em Decision Support Systems, Elsevier, 47(4):547-553, 2009.
Disponível em: [Web Link]![]()
Citação:
P. Cortez, A. Cerdeira, F. Almeida, T. Matos e J. Reis.
Modelagem de preferências de vinho por mineração de dados de propriedades
físico-químicas. Em Decision Support Systems, Elsevier, 47(4):547-553, 2009.
Paulo Cortez, Universidade do Minho, Guimarães, Portugal, www3.dsi.uminho.pt/pcortez ![]()
A. Cerdeira, F. Almeida, T. Matos e J. Reis, Comissão de Viticultura da Região dos Vinhos Verdes (CVRVV) , Porto, Portugal
@2009
COLETA E ANÁLISE
Status da atividade:
Visão gestor:
- As variáveis são: * Acidez: Atribuída como fator com 96 níveis; * Volatilidade; * Ácido citrico; * Açucar residual; * Dióxido de enxofre livre; * Cloretos; * Dióxido de enxofre total; * Densidade; * Ph; * Sulfatos. * Alcool;
* Qualidade (resposta).
- Todas as variáveis são do tipo numérico, exceto a qualidade, que é um número inteiro.
- O maior índice de qualidade para vinho tinto fica entre 5 e 6 e para vinho branco entre 6 e 5.
- As caracteristicas mais relevantes são: fixed acidity, citric acid, chlorides e density
- Para vinho tinto: Alcool extremamente baixo (abaixo de 9)tendem estar na categoria de baixa qualidade 3, 4, 5 e 6
álcool extremamente alto (acima de 14) tendem a estar em categorias altas de qualidade 5,6,7 e 8.
Visão Engenheiro de Software:
- Verificar a disponibilidade das variáveis listadas na etapa anterior.

Conjunto de dados sobre Vinho da UCI Machine Learning Repository
- Modelar(se não existir) o DW/Data Mart,
 Modelos Informacionais das carcterísticas sensoriais do vinho
Modelos Informacionais das carcterísticas sensoriais do vinho
definir o processo de ETL

processo de ETL
Caracteristicas em ambos arquivos (registo 0 - winequality-red[0]:
"acidez fixa";"acidez volátil";"ácido cítrico";"açúcar residual";"cloretos";"dióxido de enxofre livre";"dióxido de enxofre total";"densidade";"pH";"sulfatos";"álcool ";"qualidade"
* Download
do conjunto de dados sobre Vinho Tinto ( winequality-red.csv )
Exemplo:
6,7;0,675;0,07;2,4;0,089;17;82;0,9958;3,35;0,54;10,1;5
* Download
do conjunto de dados sobre Vinho Branco ( winequality-white.csv )
Exemplo:
5,8;0,27;0,2;14,95;0,044;22;179;0,9962;3,37;0,37;10,2;5
e integrá-lo a uma ferramenta.

Integração com ferramenta de análise
- Analisar os dados Perguntas a serem respondidas:
- Saber quantas amostras foram contadas? (valor enviado:vinho tinto - 1599; vinho branco - 4898
- Quais são as 5 primeiras amostras mostrando as caracteristicas?
- Veio faltando algum valor de caracteristica?
- Veio faltando alguma classificação?
- Gerar uma tabela com faixa de valores por tipo de caracterista
-
- De quanto é a diferença entre as amostras?
- Comparar valores das caracteristicas entre tinto e branco para classificação 10.
- Comparar valores das caracteristicas entre tinto e branco para classificação 1.
- Estatísticas Descritivas
- Visualizações Unimodais
- Visualizações Multimodais
- Outras
- Uso da plataforma Colab do Google para coletar e analisar os dados
- NumPy: computação matemática (arrays).
- SciPy: computação científica (álgebra linear).
- Pandas: manipulação e análise de dados, o "excel" do Python
- Matplotlib: visualização de dados (gráficos)
- Seaborn: visualização de dados (gráficos)
Visão analista esatistico:
A. Validação das amostras enviadas, separando vinho tinto do branco:
Tipos de Análise:
 Analistas
Analistas
Resposta

PRÉ PROCESSAMENTO
Status da atividade:
Visão gestor:
- As variáveis são: * Acidez: Atribuída como fator com 96 níveis; * Volatilidade; * Ácido citrico; * Açucar residual; * Dióxido de enxofre livre; * Cloretos; * Dióxido de enxofre total; * Densidade; * Ph; * Sulfatos. * Alcool;
* Qualidade (resposta).
- As caracteristicas mais relevantes são: fixed acidity, citric acid, chlorides e density
Visão analista estatístico:
- Remover ou inputar dados faltantes e tratar dados inconsistentes.
- Corrigir ou amenizar outlierse desbalanceamento entre classes
- Selecionar as variáveis e instâncias para compor o(s) modelo(s).
Analistas
Resposta
Plataforma Google Colab
Book da Atividade 2: -
Para ver seleção de caracteristicas
Clicar aqui
- NumPy: computação matemática (arrays).
- SciPy: computação científica (álgebra linear).
- Pandas: manipulação e análise de dados, o "excel" do Python
- Matplotlib: visualização de dados (gráficos)
- Seaborn: visualização de dados (gráficos)
- Missingno: para tratamento de missings
- Sklearn: para aprendizado de máquina
Técnicas de Pré-processamento
- Limpeza
- Agregação
- Amostragem
- Redução de dimensionalidade
- Seleção de características
- Criação de recursos
- Transformação
- Enriquecimento
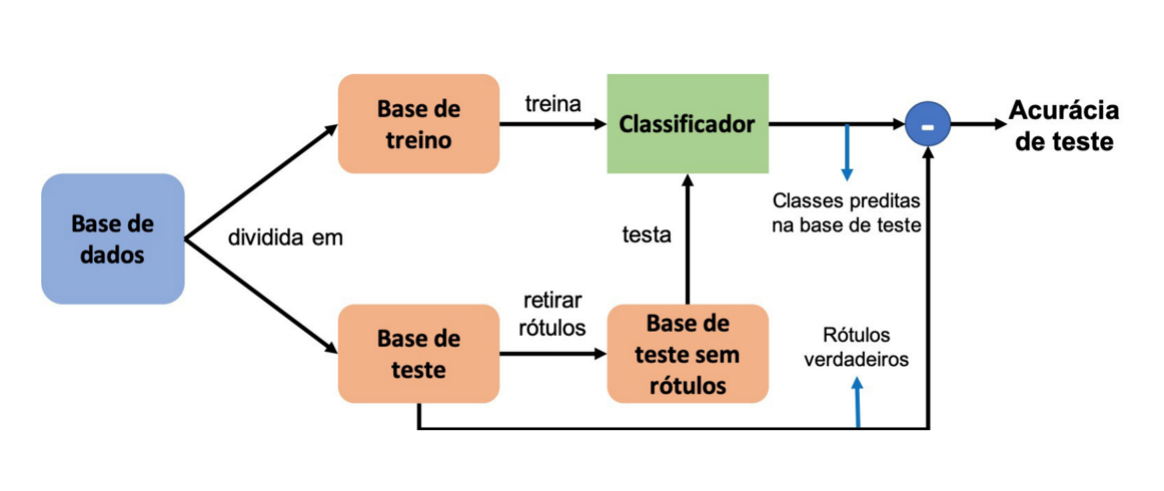
Particionamento do conjunto de dados - Pipe line inicial
MODELAGEM E INFERÊNCIA
Status da atividade:
Visão gestor:
- De modo a reduzir a dimensionalidade dos dados e selecionar as variáveis com maior poder de explicação da variabilidade, pois variáveis sensoriais podem apresentar altas correlações.
- Todas as covariáveis disponibilizadas no conjunto de dados são atribuídas como fator, com exceção da qualidade, que deve ser transformada.
- A maior concentração de vinhos tem qualidade 5 e 6.
- As variáveis que mais contribuíram para a construção de cada componente do modelo, foram: densidade e Dióxido de enxofre total.
Visão analista estatístico:
- Listar os modelos possíveis e passíveis para cada tipo de problema.
- Estimar os parâmetros que compõem os modelos, baseando-se nas instâncias e variáveis pré-processadas.
- Avaliar os resultados de cada modelo, usando métricas e um processo justo de comparação.
Analistas
Resposta
- LR: Regressão Logística LogisticRegression(max_iter=200).
- KNN: K-vizinhos mais próximos KNeighborsClassifier().
- CART: Árvores de classificação DecisionTreeClassifier()
- NB: K-vizinhos mais próximos GaussianNB()
- SVM: Máquinas de vetores de suporte SVC()
Particionamento do conjunto de dados - Pipe line

Interação validação cruzada

PÓS PROCESSAMENTO
Status da atividade:
- Combinar heurísticas de negócio com os modelos ajustados.
- Pós-avaliar tendo em vista os pontos fortes e dificuldades na implementação de cada um dos modelos.
Analistas
Resposta
Plataforma Google Colab
Book da Atividade 2: -
APRESENTAÇÃO DE RESULTADOS
Status da atividade:
- Relatar a metodologia adotada para endereçar a solução às demandas dos gestores
- Comparar os resultados do melhor modelo com o benchmark atual (caso haja)
- Planejar os passos para a implantação da solução proposta
Entre 1.599 obeservações de vinhos, 82,4% dos vinhos receberam pontuação de 5 ou 6. Cerca de 4% dos vinhos receberam pontuação 3 ou 4 e 13,6% dos vinhos receberam pontuação de 7 ou 8. Seria melhor ter uma variedade maior de índice de qualidade para o conjunto de dados.
Vários métodos de mineração de dados foram aplicados ao modelo estes conjuntos de dados sob uma abordagem de regressão.
O modelo de máquina vectorial de suporte alcançou o melhores resultados. Várias métricas foram computadas: MAD, matriz de confusão para uma tolerância de erro fixa (T), etc.
Além disso, foram traçadas as importâncias relativas das variáveis de entrada (medidas por uma sensibilidade procedimento de análise).
Estes conjuntos de dados podem ser vistos como tarefas de classificação ou de regressão.
As classes são ordenadas e não equilibradas (por exemplo, há mais vinhos normais do que excelentes ou pobres).
Algoritmos de detecção poderiam ser utilizados para detectar os poucos excelentes ou vinhos pobres.
Além disso, não há certeza se todas as variáveis de entrada são relevantes. Por isso poderia ser interessante testar métodos de selecção de características.
Para futuras análises futuras, seria interessante e significativo combinar ou comparar esse conjunto de dados com o conjunto de dados (dataset) de vinho branco.
Então, poderá ser visto como esses produto químicos (vinho) tem correlação das propriedades com a qualidade alterada.
IMPLANTAÇÃO DO MODELO E GERAÇÃO DE VALOR
Status da atividade:
- Implantar o modelo em produção (Grupos de processamento online e em lote (batch)
- Calcular os ganhos qualitativos (ganhos operacionais e de recursos humanos) e quantitativos (ROI e outras métricas)
- Monitorar o modelo implantado
Treinamento / Produção
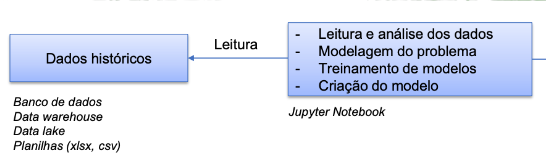

Visão geral do sistema em operação

Procedimento para produção
Grupo de processamento 1
| Periodicidade: | Aleatória |
|---|---|
| Condição de ativação: | Solicitação de pontuação |
| Pré-requisito: | Ter as amostras de vinho tinto |
| Entrada: | Conjunto de valores de cada caracteristica e avaliação de vinho tinto winequality-red.csv |
| Executor: | Colab |
| Saida: | Classificação das amostras |
| Verifique: | Resultado da classificação |
| No caso de erro: | Chamar analista responsável pelo evento |
| Ação: | Rejeitar se amostra for menor que [6 6 6]: |
Grupo de processamento 2
| Periodicidade: | Aleatória |
|---|---|
| Condição de ativação: | Novas amostras disponíveis |
| Pré-requisito: | Amostras anteriores acima da média (entre 6 e 10) winequality-red.csv |
| Entrada: | Formulário com conjunto de valores de cada caracteristica e avaliação de vinho tinto |
| Executor: | Colab |
| Saida: | Classificação das amostras |
| Verifique: | Resultado da classificação |
| No caso de erro: | Chamar analista responsável pelo evento |
| Ação: | Rejeitar se amostra for menor que [6 6 6]: |
Grupo de processamento 3
| Periodicidade: | Aleatória |
|---|---|
| Condição de ativação: | Novas amostras disponíveis |
| Pré-requisito: | Amostras anteriores guardadas em winequality-red.csv |
| Entrada: | |
| Executor: | Colab |
| Saida: | Acuracidade do modelo |
| Verifique: | Valor da Acuracidade |
| No caso de erro: | Chamar analista responsável pelo evento |
| Ação: | Alterar modelo se acuracidade < 52,00 % |
ACOMPANHAMENTO DO DESENVOLVIMENTO
Padrão:
Situação atual:
Status por atividade:
Definição da solução
Coleta e análise de dados
Pré-processameto
Modelagem e inferência
Pós-processamento
Apresentação de resultados
Impantação do modelo
REFERÊNCIAS

-
Domínios do conhecimento
-
Domínios
-
Wikipedia
-
Web
-
Ciência de dados
-
Engenharia de Software para Ciência de Dados
-
Escovedo, Tatiana; Koshyama, Adriano. Introdução a Data Science. Casa do código, 2014
[Web]
-
Atividade 2
-
Seleção de caracteristica
-
Modelo de Produção
-
Análise exploratória com Pandas
-
Visualização de dados
-
Análise exploratória e Visualização de dados
-
Pré-processamento - Normalização e Padronização
-
Pré-processamento - caso diabetes
-
Classificação (usando holdout)
-
Regressão
-
Modelo de classificação simples usando POO
-
Projeto completo de classificação diabetes
-
Colocando modelo em producao
-
Atividade 2
-
Seleção de caracteristica
-
Resumo Ciência de dados
-
Algebra para ciência de dados
-
A diferença entre cientistas de dados, engenheiros de dados, estatísticos e engenheiros de software
-
Pdf
-
Sistemas de Informação
-
Conceitos sistema de informação
-
Teoria geral dos sistemas
-
Creatividade em sistema de informação
-
Teoria geral
-
Sistema
-
Web
-
Ciência da informação
-
ELsevier
-
Ciência da informação
-
Almeida, Mauricio Barcelos. Representação do Conhecimento, Ontologia e Linguagem. Ed CRV. 2020
-
Meirelles, Isabel. Design for information. Rockport. 2013
-
Visualização da informação
-
Relatório sobre Visualização de Informação
-
Teoria da informação
-
Artigos
-
Revistas
-
Wikipedia
-
Representação da informação
-
Livros
-
Design da informação
-
Livros
-
Web
-
Ciência da computação
-
Brookshear, J. Glenn. Ciência da Computação - Uma visão abrangente. Bookman ed. 11 ed, 2013
-
Algoritmos
-
Introdução ao Python
-
Melhorias em programas PEP-8
-
Nomenclatura
-
Uso de modulos
-
Compreender e melhorar a qualidade e a reprodutibilidade dos notebooks Jupyter
-
requirements.txt
-
Clássicos
-
Geral
-
Livros
-
Algoritmos
-
Web
-
Colab
-
Design de Sistema
-
UX Design e Inovação
-
Experiência do usuário (UX)
-
Pdf
-
Engenharia de Software
-
Pressman, Rogers S. e Maxim, Bruce R. Engenharia de software uma abordagem profissional. McGraw Hill Brasil. 9a Ed. 2020
-
Pressman, Rogers S. e Maxim, Lowe, David Engenharia Web. Gen/LTC. 2009
-
Engenharia de software (SWEBOK Guide V3 Topics)
-
Engenharia de Software para Ciência de Dados
-
Modelo conceitual de requisitos
-
WAGNER, S.; FERNÁNDEZ, D. M.; FELDERER, M.; VETRO, A.; KALINOWSKI, M.; WIERINGA, R.; PFAHL, D.;
CONTE, T.; CHRISTIANSSON, M.; GREER, D.; LASSENIUS, C.; MÄNNISTÖ, T.; NAYEBI, M.; OIVO, M.;
PENZENSTADLER, B.; PRIKLADNICKI, R.; RUHE, G.; SCHEKELMANN, A.; SEN, S.; SPÍNOLA, R. O.; TUZCU, A.;
DE LA VARA, J. L.; AND WINKLER, D. Status Quo in Requirements Engineering: A Theory and a Global
Family of Surveys. ACM Transactions on Software Engineering and Methdology, 28(2): 9:1-9:48. 2019.
-
Amershi, S., Begel, A., Bird, C., et al., Software engineering for machine learning: A case
study. In IEEE/ACM International Conference on Software Engineering: Software Engineering in
Practice (ICSE-SEIP), 2019
-
Teixeira, Júlio Monteiro. Gestão visual de projetos - utilizando a informação para inovar. Alta books ed, 2018
[Web]
-
Aguiar, Fábio; Caroli, Paulo. Product Backlog Bilding, Ed Caroli, 1a Ed, 2021.
-
Caroli, Paulo e Lean Inception. Ed Caroli, 1a Ed, 2018
-
Massari, Victor L. ; Vidal, André. Gestão Agil de Produtod. Ed Brasport; 2018
-
Revista de Sistemas e Software
-
Alonso, S., Kalinowski, M., Viana, M., Ferreira, B. and Barbosa, S. D. J. A Systematic Mapping
Study on the Use of Software Engineering Practices to Develop MVPs, Euromicro Conference
on Software Engineering and Advanced Applications (SEAA), 2021
-
Amershi, S., Begel, A., Bird, C., et al., Software engineering for machine learning: A case
study. In IEEE/ACM International Conference on Software Engineering: Software Engineering in
Practice (ICSE-SEIP), 2019
-
Clássicos
-
Geral
-
Livros
-
Pdf
-
Web
-
Livros
-
Artigos
-
Revistas
-
Rede Internacional de Engenharia de Software
-
Rede Internacional de Pesquisa em Engenharia de Software (ISERNE)
-
Simpósio Internacional de Engenharia e Medição de Software Empírico (ESEM)
-
Web
-
Engenharia de Sistemas e Computação
-
Blanchard, Benjamin S. Fabrycky, Wlter J.; Systems Engineering and Analysis; Ed Person ; 2006
-
Engenharia de sistema e computação (Incose)
-
Clássicos
-
Geral
-
Livros
-
Conselho Internacional de Engenharia de Sistemas
-
Web
-
Matemática, Estatística e Python
-
Algebra para ciência de dados
-
Algebra com python
-
Equação da reta, curva e fibonacci
-
Como escolher seu gráfico
-
Explicação o que é cross_val_score-sklearn?
-
Gráficos enganosos
-
Algebra
-
Web
-
WEB
-
Vinícula
-
Uso da ML na indutria vinícula
-
Modelo de classificação de vinho
-
Modelo de classificação de vinho outro exemplo
GitHub
-
Web
-
Laboratórios
-
Laboratório de Engenharia de Software LES
Software Science Lab
ExACTa
-
Web
-
Cursos
-
Engenharia de Software para Ciência de Dados
Análise e Projeto de Sistemas
Catálogo Integencia artificial
-
Zoom
GLOSSÁRIO DE TERMOS
| ID | Item | Tema | Significado |
|---|---|---|---|
| 1 | Acidez fixa. | Elementos quimicos | . É a soma dos ácidos fixos, que são os mais importantes, chamados de Tartárico e Málico. Quanto mais elevada for a acidez fixa, mais baixa será a acidez volátil, que também é levada em conta pela base de dados. Quanto maior a quantidade dos ácidos maior será a dificuldade para as bactérias acéticas se desenvolverem |
| 2 | Acidez voláti | Elementos quimicos | É a soma dos ácidos voláteis, que se libertam por forma de ebulição ou destilação do vinho e traduz o nível de ataque aceto bacteriano ao vinho. O valor máximo permitido por lei é de 1,2 gramas de ácido acético por litro de vinho. |
| 3 | Acido cítrico | Elementos quimicos | É um ácido orgânico forte, normalmente presente em fracas quantidades nos mostos de uva e geralmente ausente nos vinhos. A sua concentração aumenta ligeiramente a fermentação do álcool no vinho. A adição do ácido cítrico é degradável pela grande maioria das bactérias lácticas do vinho. |
| 4 | Açúcar residual | Elementos quimicos | A concentração residual do açúcar no vinho refere-se à quantidade de sólidos de açúcar em um determinado volume de vinho após o final da fermentação, além de qualquer adição de açúcar. Sua principal função é equilibrar o sabor ácido do vinho tendo um impacto muito importante na sua qualidade. |
| 5 | Cloretos | Elementos quimicos | Geram no vinho um gosto salgado que pode causar uma reação negativa dos consumidores. Se a concentração ultrapassar certos limites o vinho não terá permissão para ser comercializado. |
| 6 | Dióxido de enxofre | Elementos quimicos | É o resultado da fermentação do vinho. A maioria dos produtores utilizam o dióxido de enxofre como um conservante do vinho. Uma grande característica do dióxido de enxofre é trazer condições melhores para os processos de vinificação do vinho, elimina bactérias e leveduras frágeis e indesejáveis, o que permite que apenas as melhores prossigam com o processo de fermentação. |
| 7 | Densidade | Elementos quimicos | A densidade do vinho está relacionada ao seu teor alcoólico e de açúcares residuais do mesmo. |
| 8 | pH | Elementos quimicos | O pH, em termos simples, mede a força da acidez. Sua escala pode variar de 0 a 14, com 0 sendo muito ácido e 14 alcalino. O valor do pH sendo 7 é uma solução neutra, vinhos normalmente variam de 2,8 a 4,0. |
| 9 | Sulfatos | Elementos quimicos | Eles formam-se naturalmente em comidas e bebidas, como resultado da fermentação do vinho. A maioria dos produtores utilizam o sulfitos com o dióxido de enxofre para conservar o vinho |
| 10 | Alcool | Elementos quimicos | O álcool é resultado da fermentação sem oxigênio do vinho, chamada de fermentação alcoólica, em que o açúcar contido nas frutas é transformado em etanol. Essa conversão é feita através de uma complexa série de reações químicas |
| 11 | Qualidade | Qualidade | A qualidade do vinho é avaliada neste banco de dados por especialistas que dão uma nota ao saborear os vinhos analisados (0 a 10 ruim , médio e bom). Eles analisam conforme o sabor, textura e aspectos físicos do vinho. |
| 12 | Análise univariada | Estatística |
Descrevemos a população examinando uma variável por vez. É a maneira mais simples de restituir a informação e de fazer a estimativa estatística. Envolve descrever a distribuição de uma única variável, incluindo sua medida central(incluindo a média,mediana, e a Moda (estatística) e dispersão(incluindo a diferença entre o maior e menor valor da amostragem e quantil do conjunto de dados, além da variância e desvio padrão). |
| 13 | Análise bivariada | Estatística |
A análise bivariada (2 variáveis) é uma das formas mais simples de análise quantitativa. Envolve a análise de duas variáveis, com o objetivo de determinar a relação empírica entre elas. A análise bivariada pode ser útil para testar hipóteses simples de associação. É usada para fins de explicação e/ou previsão Esta análise tanto pode ser feita em termos de distribuição (para duas variáveis ordinais) como em termos de frequências para variáveis nominais. |
| 14 | Análise multivariadas | Estatística |
Usa informações de várias fontes, simultaneamente, para obter uma imagem melhor, mais completa e mais otimizada do ambiente. Utilizada quando se necessita descrever a associação entre duas ou mais variáveis. |
| 15 | Análise de dados | Estatística |
Análise descritiva. O tipo de análise mais frequentemente usada, tanto no meio acadêmico quanto no empresarial, é a descritiva. Análise prescritiva. ... Análise preditiva. ... Análise diagnóstica. |
| 16 | Abordagem de análise de dados | Estatística |
Qualitativa. Oferece três diferentes possibilidades de se realizar pesquisa: a pesquisa documental, o estudo de caso e a etnografia Variável qualitativa nominal = valores que expressam atributos, sem nenhum tipo de ordem. Ex: cor dos olhos, sexo, estado civil, presença ou ausência... - Variável qualitativa ordinal = valores que expressam atributos, porém com algum tipo de ordem, ou grau. Quantitativa. é o uso de um conjunto de métodos e modelos matemáticos e estatísticos para estudar e monitorar comportamentos de mercado e identificar oportunidades de investimentos Variável Quantitativa nominal = valores que expressam atributos, sem nenhum tipo de ordem. Ex: cor dos olhos, sexo, estado civil, presença ou ausência... Variável qualitativa ordinal = valores que expressam atributos, porém com algum tipo de ordem, ou grau. Variáveis quantitativas discretas – quando resultam de um conjunto finito (ou enumerável) de valores possíveis. Variáveis quantitativo correlacional, o objetivo é coletar dados que evidenciem ou neguem uma relação entre fenômenos, que podem ou não serem previstos. Desse modo, ela se baseia normalmente em tendências, padrões de comportamento ou relacionamentos em geral. |
| 17 | Variáveis | Estatística |

|
| 18 | Pesquisa | Pesquisa |

|
| 19 | Distribuição modal | Estatística |
A moda pode ser unimodal, bimodal ou multimodal para mostrar a frequencia: A unimodal envolverá a escolha dos valores de mais alta densidade probabilística, incluindo a moda. Amodal: não possui moda: Multimodal possui mais do que dois valores modais. EXEMPLO: A moda de {maçã, banana, laranja, laranja, laranja, pêssego} é laranja. Observe que três pessoas receberam rendimento de 30, três pessoas receberam 50, duas pessoas receberam 32. Percebam que os números 30 e 50 se repetem três vezes cada um. Isso significa que o conjunto possui duas modas (30 e 50) e é chamado de bimodal. Histogramas são usados para mostrar a frequência com que algo acontece. |
| 20 | BoxPlot | Estatística |
Em estatística descritiva, diagrama de caixa, diagrama de extremos e quartis, boxplot ou box plot é uma ferramenta gráfica para representar a variação de dados observados de uma variável numérica por meio de quartis. O centro da distribuição é indicado pela linha da mediana, no centro do quadrado. A dispersão é representada pela amplitude do gráfico, que pode ser calculada como máximo valor – mínimo valor. Quanto maior for a amplitude, maior a variação nos dados.  |
| 20 | Pipeline | Software |
O pipeline de inovação é um caminho percorrido pelas ideias de um negócio, até se tornarem iniciativas concretas. Ele possui etapas nas quais o projeto pode ser descartado ou reformulado senão demonstrar a viabilidade esperada. Um pipeline de DevOps é um conjunto de processos e ferramentas automatizados que permite que desenvolvedores e profissionais de operações colaborem na criação e implementação de código em um ambiente de produção. Um pipeline tem como objetivo mover os dados de um lugar para outro, e geralmente é similar ao conceito de ETL (extract, transform, load). Permite ter uma visão de todas as fases de um processo |
| 21 | Framework | Organização empresarial | É uma estrutura para conteúdo e processo que pode ser usada como uma ferramenta para estruturar o pensamento e garantir consistência e completude. Arquitetura de Zachman |
| 22 | Sistemas | Sistema |
É qualquer coisa que possa ser dividido funcionalmente e que as partes se interrelacionam através de interfaces para atender ou perseguir um objetivo externo ou interno, que pode ser influenciada por um ambiente externo e/ou interno. Exemplo: Sistema de análise de sistema 
|
| 23 | Tipos de sistemas | Sistema | É uma estrutura para conteúdo e processo que pode ser usada como uma ferramenta para estruturar o pensamento e garantir consistência e completude. Tipos de Sistemas |
| 24 | Grupo de Processamento | Sistema | Conjunto de operações interdependentes de mesma periodicidade, a serem executadas em sequência, cuja continuidade de elementos vindos de outros grupos, de outra unidade de produção ou do Cliente/Usuário. |
| 25 | Grupo de Desenvolvimento | Sistema | Auxilia planejamento do desenvolvimento do sistema, podendo conter um número inteiro de grupos de Processamento ou constituido parcela de um grupo de Processamento, caso em que deve conter pelo menos uma operação (sequência de passos ou programas, dirigidos a uma única meta, que se tenta atingir repetidas vezes) . |
| 26 | Arquivos no python | Python |

.py: normalmente o código fonte de entrada que você escreveu. Ex: nome_programa.py módulo é um arquivo contendo definições e instruções Python. Ex:o nome do arquivo que contém o modulo é chamado nome_modulo.py .Pode conter uma ou mais funções ou várias instruções. Para chamar colocar import nome_modulo . .pyc: é o bytecode compilado. Se você importar um módulo o Python construirá um arquivo *.pyc que contém o bytecode para depois ficar mais fácil e mais rápido. .pyo: é um arquivo *.pyc que foi criado com otimizações ativadas (-O). pacote é um arquivo contendo varios arquivos .py .pkl: é um arquivo chamado pacote que contem vários programas .py |
| 27 | Estrutura operacional e desenvolvimento do sistema | Sistema |
Estrutura Operacional do Sistema de Informação e estrutura do método de desenvolvimento do sistema |
EVOLUÇÃO DESTE ESFORÇO
- Documento digital de aplicação de machine-learning "ML" para o acervo de alguma biblioteca digital.
- Site de apoio para algum livro sôbre aplicação de "ML".
- Objeto de aprendizagem de aplicação "ML".
- Mapeamento da experiência de uma aplicação "ML" para projeto de pesquisa.
- Processo para especificação de desenvolvimento de um projeto de "ML".
- Sistema para fazer um sistema de aplicação de "ML" (metodologia).
- Serviço de "ML" para uma aplicação de "ML".
- Protótipo para uma start-up transformar em um negócio de serviços de aplicações de "ML".